


Since the launch of ChatGPT in 2022, technological innovations in LLM (Large Language Models) and generative AI have been progressing daily, and the social situation surrounding them is also changing rapidly.
In order to strengthen efforts toward the social implementation of these technologies and to support companies, BrainPad is also conducting a technology research project on LLM/generative AI, and is continuously catching up on the latest trends and sharing information.In this series, I will pick out and introduce case studies, technologies, and news that I personally find interesting from the topics that come up in our weekly study sessions.
Latest trends in generative AI/LLM technology in 2024
1. Llama 3 released
On April 18, US company Meta released the large-scale language model “Llama 3.” Two models are available, one with 8 billion parameters and the other with 70 billion parameters, and each model boasts the highest performance among open source LLMs of the same model size.

Table source: https://ai.meta.com/blog/meta-llama-3/
Additionally, the performance of the 70 billion model ranks fifth among all currently publicly available models.
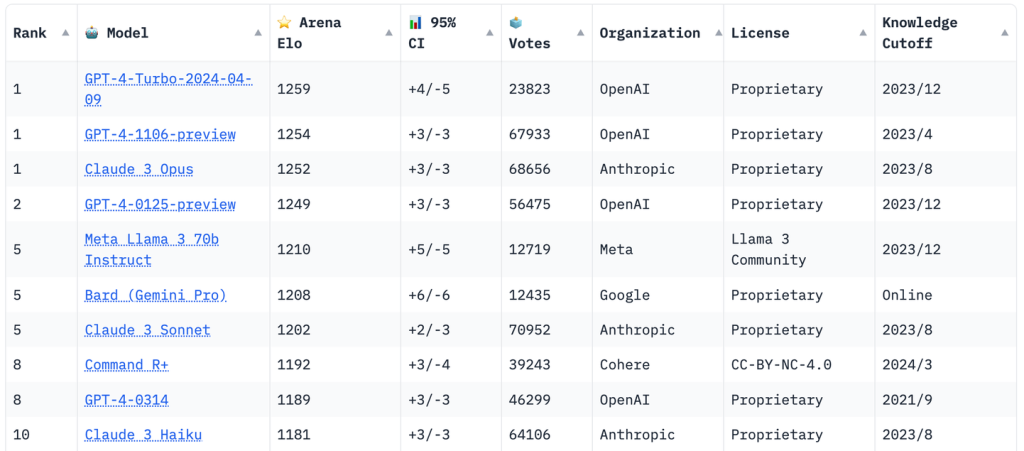
Table source : https://chat.lmsys.org/?leaderboard
A model with 400 billion parameters is currently being trained, and I can imagine that it will become a big topic once it is completed.
Various models are being announced at an unimaginable speed. I can’t take my eyes off it.
2. Reliability of the RAG model
The phenomenon in which AI generates information that is not based on facts is called “hallucination. ” In recent years, a technology called RAG has begun to be used as one way to mitigate the problem of hallucination.
RAG (retrieval-augmented generation) is a technology that combines text generation using LLM with searching for external information.
The search target can be set arbitrarily, so RAG makes it possible to generate answers using the latest information, internal company documents, etc. In fact, this RAG technology is used in many of the chatbots and internal information search tools that use LLM and are currently being released around you.
Now, this is a useful RAG model, but if there is a contradiction between the external information referenced and the internal knowledge held by the LLM, which information will the LLM believe and output ?
A paper answering this question has been published. I will provide a brief overview.
In this paper, we analyze the relationship between the internal knowledge (prior knowledge) of the LLM and the information provided by the RAG under circumstances where there is a discrepancy between the two. We tested the question-answering ability of LLMs such as GPT-4 with and without reference documents and analyzed the responses of the LLMs by gradually adding false information to the reference documents.
As a result, we learned the following three things:.
- The tendency of LLMs to rely on RAG information (RAG preference rate) is negatively correlated with the confidence of LLMs in their prior knowledge (prior probability).
- The more the RAG information deviates from prior knowledge, the more likely LLM is to rely on prior knowledge.
- The way the prompt is written (strictly following the RAG, loosely following the RAG, etc.) also influences the rate of RAG preference.
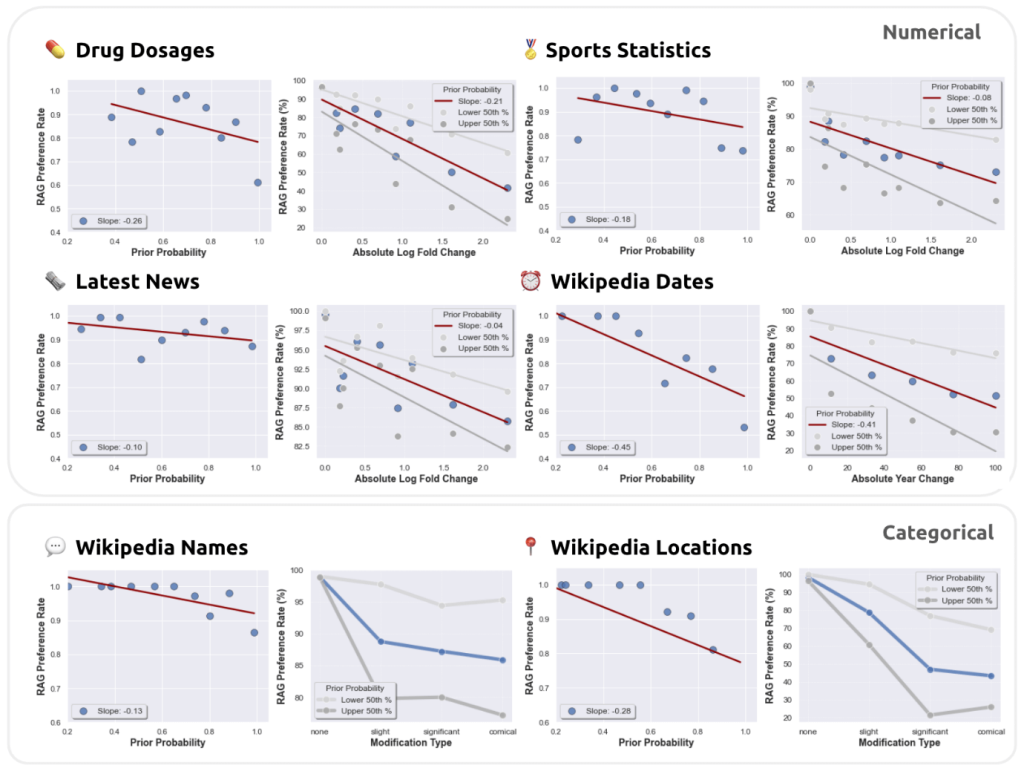
Source of graph: p.3 of the same paper. We used GPT-4 to gradually add misinformation to the reference documents in six QA datasets. The y-axis shows the RAG priority, the x-axis shows the confidence of the model’s prior knowledge in the left graph, and the divergence between the prior knowledge and the reference documents in the right graph. Negative correlation is observed in both cases.
I feel that they are similar to humans in the sense that when they believe their knowledge is correct, they trust their knowledge, and when they are anxious, they rely on information provided from outside. Based on these results, the paper makes the following observations:
- While the RAG system is effective in suppressing hallucination in LLMs, the LLM’s prior knowledge may take precedence over the RAG information, and the RAG system does not always provide accurate information .
- It is not clear how the LLM combines reference documents and prior knowledge , which may lead to unexpected results.
- In fields such as medicine and law, the reliability of RAG systems needs to be carefully considered.
In areas where accuracy is highly required for the output results and deep expertise is required, unexpected output errors may lead to serious accidents. It was previously reported in the news that GPT-4 achieved scores at the level of passing the bar exam and the national medical exam, but it seems that human checks are still necessary for practical use.
As research into the relationship between LLM and RAG progresses in the future, will we be able to avoid outputting erroneous information and derive correct results? I look forward to future research developments.
3. Introducing AutoCrawler, a framework for using generative AI for web crawling
Have you ever tried web crawling/scraping?
Web crawling is a technique that periodically visits websites to obtain specific information . It can obtain a large amount of required information quickly, and can be easily implemented using Python etc., greatly reducing the time required for data collection.
I am also a software engineer, so my work often involves research tasks. It takes a lot of time to gather information, but crawling and scraping can help reduce unproductive time.
A paper has been published introducing a framework called “AutoCrawler” that uses LLM to efficiently generate the scripts (crawlers) required for crawling . I will provide a brief overview.
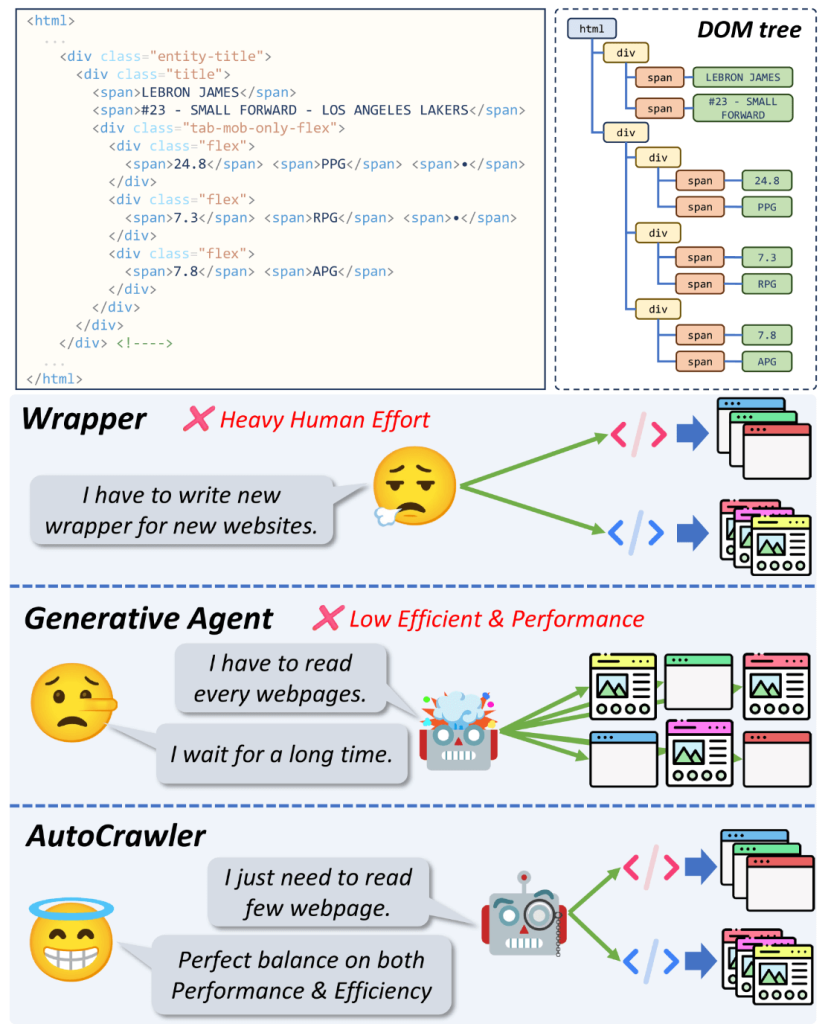
Traditional web crawling uses a technique called a wrapper, which is a script or software designed specifically to extract data from a specific website or page. While crawling a web page with a fixed format can efficiently retrieve information, if the format of the web page changes, a new script must be written each time, which places a heavy burden on users.
Meanwhile, the emergence of LLMs has made it possible to create crawling agents that can autonomously navigate, interpret, and interact with web pages, but these have issues with low performance and low reusability (repeating the same process over and over to perform similar tasks).
AutoCrawler allows you to retrieve information with both performance and efficiency.
The AutoCrawler introduced in this paper aims to improve the crawler’s performance by dividing the process into two stages: the “gradual generation phase,” which learns from erroneous actions through operations, and the “synthesis phase,” which runs these processes multiple times to generate versatile actions .
1. Incremental generation phase
A top-down operation generates an XPath* to the node that contains the target information. If the operation fails, a step-back operation goes back up the hierarchy, selects a node that contains the relevant information, and regenerates the XPath. This is repeated until it succeeds.
*XPath (XML Path Language) is a language for selecting specific elements or attribute values from the tree structure of XML or HTML documents. This is particularly useful for retrieving information from web pages.
2. Synthesis phase
It executes an operation on multiple web pages and synthesizes a versatile action sequence based on the results.
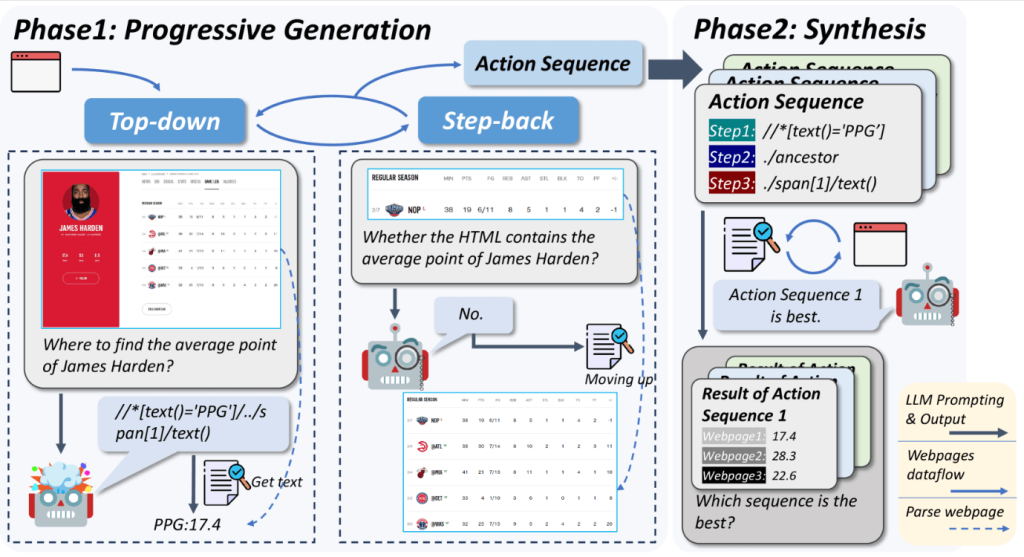
Figure source: p.3 of the same paper
These experiments show that AutoCrawler can generate more accurate and executable action sequences compared to previous frameworks, and also show that it can achieve more stable performance on large-scale LLMs.
On the other hand, it also became clear that LLM alone is not good at understanding the structure of web pages. As the performance of LLM improves, will the accuracy of structural understanding improve in the future? We look forward to future developments.
summary
Thank you for reading to the end.
Today, I have introduced three topics: the release of Llama3, the reliability of the RAG model, and AutoCrawler.
Through its research projects on LLM/Generative AI, BrainPad will act as a digital transformation partner for companies by verifying new technologies and supporting the promotion of digital transformation for companies.
We will be introducing the latest information in the next installment of this series. Stay tuned!